量化金融与金融编程
L5 dplyr1.0.10 数据处理
曾永艺
厦门大学管理学院
2022-10-21
A Grammar of
Data Manipulation
A Grammar of
Data Manipulation
样本处理
变量处理
汇总
分组和行式处理
用
%>%连接多个操作合并多个数据集
操作数据库和
data.table
library(tidyverse)library(nycflights13)data(package = "nycflights13")# 包含airlines、airports、flights、planes、weather等5个数据集flights#> # A tibble: 336,776 × 19#> year month day dep_t…¹ sched…² dep_d…³ arr_t…⁴ sched…⁵ arr_d…⁶ carrier flight tailnum#> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr> <int> <chr> #> 1 2013 1 1 517 515 2 830 819 11 UA 1545 N14228 #> 2 2013 1 1 533 529 4 850 830 20 UA 1714 N24211 #> 3 2013 1 1 542 540 2 923 850 33 AA 1141 N619AA #> # … with 336,773 more rows, 7 more variables: origin <chr>, dest <chr>, air_time <dbl>,#> # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>, and abbreviated variable#> # names ¹dep_time, ²sched_dep_time, ³dep_delay, ⁴arr_time, ⁵sched_arr_time, ⁶arr_delaylibrary(tidyverse)library(nycflights13)data(package = "nycflights13")# 包含airlines、airports、flights、planes、weather等5个数据集flights#> # A tibble: 336,776 × 19#> year month day dep_t…¹ sched…² dep_d…³ arr_t…⁴ sched…⁵ arr_d…⁶ carrier flight tailnum#> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr> <int> <chr> #> 1 2013 1 1 517 515 2 830 819 11 UA 1545 N14228 #> 2 2013 1 1 533 529 4 850 830 20 UA 1714 N24211 #> 3 2013 1 1 542 540 2 923 850 33 AA 1141 N619AA #> # … with 336,773 more rows, 7 more variables: origin <chr>, dest <chr>, air_time <dbl>,#> # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>, and abbreviated variable#> # names ¹dep_time, ²sched_dep_time, ³dep_delay, ⁴arr_time, ⁵sched_arr_time, ⁶arr_delay
A tibble: 336,776 x 19<int>|<dbl>|<chr>|<dttm>|<lgl>|<fctr>|<date>分别表示变量为 integer | double | character | date-time | logical | factor | date 类型的向量
library(tidyverse)library(nycflights13)data(package = "nycflights13")# 包含airlines、airports、flights、planes、weather等5个数据集flights#> # A tibble: 336,776 × 19#> year month day dep_t…¹ sched…² dep_d…³ arr_t…⁴ sched…⁵ arr_d…⁶ carrier flight tailnum#> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr> <int> <chr> #> 1 2013 1 1 517 515 2 830 819 11 UA 1545 N14228 #> 2 2013 1 1 533 529 4 850 830 20 UA 1714 N24211 #> 3 2013 1 1 542 540 2 923 850 33 AA 1141 N619AA #> # … with 336,773 more rows, 7 more variables: origin <chr>, dest <chr>, air_time <dbl>,#> # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>, and abbreviated variable#> # names ¹dep_time, ²sched_dep_time, ³dep_delay, ⁴arr_time, ⁵sched_arr_time, ⁶arr_delay
A tibble: 336,776 x 19<int>|<dbl>|<chr>|<dttm>|<lgl>|<fctr>|<date>分别表示变量为 integer | double | character | date-time | logical | factor | date 类型的向量
?flights # 打开flights数据集的帮助文档以进一步了解数据集,如变量的定义glimpse(flights) # 数据一瞥#> Rows: 336,776#> Columns: 19#> $ year <int> 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013,…#> $ month <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…#> $ day <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…#> $ dep_time <int> 517, 533, 542, 544, 554, 554, 555, 557, 557, 558, 558, 558, 558, …#> $ sched_dep_time <int> 515, 529, 540, 545, 600, 558, 600, 600, 600, 600, 600, 600, 600, …#> $ dep_delay <dbl> 2, 4, 2, -1, -6, -4, -5, -3, -3, -2, -2, -2, -2, -2, -1, 0, -1, 0…#> $ arr_time <int> 830, 850, 923, 1004, 812, 740, 913, 709, 838, 753, 849, 853, 924,…#> $ sched_arr_time <int> 819, 830, 850, 1022, 837, 728, 854, 723, 846, 745, 851, 856, 917,…#> $ arr_delay <dbl> 11, 20, 33, -18, -25, 12, 19, -14, -8, 8, -2, -3, 7, -14, 31, -4,…#> $ carrier <chr> "UA", "UA", "AA", "B6", "DL", "UA", "B6", "EV", "B6", "AA", "B6",…#> $ flight <int> 1545, 1714, 1141, 725, 461, 1696, 507, 5708, 79, 301, 49, 71, 194…#> $ tailnum <chr> "N14228", "N24211", "N619AA", "N804JB", "N668DN", "N39463", "N516…#> $ origin <chr> "EWR", "LGA", "JFK", "JFK", "LGA", "EWR", "EWR", "LGA", "JFK", "L…#> $ dest <chr> "IAH", "IAH", "MIA", "BQN", "ATL", "ORD", "FLL", "IAD", "MCO", "O…#> $ air_time <dbl> 227, 227, 160, 183, 116, 150, 158, 53, 140, 138, 149, 158, 345, 3…#> $ distance <dbl> 1400, 1416, 1089, 1576, 762, 719, 1065, 229, 944, 733, 1028, 1005…#> $ hour <dbl> 5, 5, 5, 5, 6, 5, 6, 6, 6, 6, 6, 6, 6, 6, 6, 5, 6, 6, 6, 6, 6, 6,…#> $ minute <dbl> 15, 29, 40, 45, 0, 58, 0, 0, 0, 0, 0, 0, 0, 0, 0, 59, 0, 0, 0, 0,…#> $ time_hour <dttm> 2013-01-01 05:00:00, 2013-01-01 05:00:00, 2013-01-01 05:00:00, 2…glimpse(flights) # 数据一瞥#> Rows: 336,776#> Columns: 19#> $ year <int> 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013, 2013,…#> $ month <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…#> $ day <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,…#> $ dep_time <int> 517, 533, 542, 544, 554, 554, 555, 557, 557, 558, 558, 558, 558, …#> $ sched_dep_time <int> 515, 529, 540, 545, 600, 558, 600, 600, 600, 600, 600, 600, 600, …#> $ dep_delay <dbl> 2, 4, 2, -1, -6, -4, -5, -3, -3, -2, -2, -2, -2, -2, -1, 0, -1, 0…#> $ arr_time <int> 830, 850, 923, 1004, 812, 740, 913, 709, 838, 753, 849, 853, 924,…#> $ sched_arr_time <int> 819, 830, 850, 1022, 837, 728, 854, 723, 846, 745, 851, 856, 917,…#> $ arr_delay <dbl> 11, 20, 33, -18, -25, 12, 19, -14, -8, 8, -2, -3, 7, -14, 31, -4,…#> $ carrier <chr> "UA", "UA", "AA", "B6", "DL", "UA", "B6", "EV", "B6", "AA", "B6",…#> $ flight <int> 1545, 1714, 1141, 725, 461, 1696, 507, 5708, 79, 301, 49, 71, 194…#> $ tailnum <chr> "N14228", "N24211", "N619AA", "N804JB", "N668DN", "N39463", "N516…#> $ origin <chr> "EWR", "LGA", "JFK", "JFK", "LGA", "EWR", "EWR", "LGA", "JFK", "L…#> $ dest <chr> "IAH", "IAH", "MIA", "BQN", "ATL", "ORD", "FLL", "IAD", "MCO", "O…#> $ air_time <dbl> 227, 227, 160, 183, 116, 150, 158, 53, 140, 138, 149, 158, 345, 3…#> $ distance <dbl> 1400, 1416, 1089, 1576, 762, 719, 1065, 229, 944, 733, 1028, 1005…#> $ hour <dbl> 5, 5, 5, 5, 6, 5, 6, 6, 6, 6, 6, 6, 6, 6, 6, 5, 6, 6, 6, 6, 6, 6,…#> $ minute <dbl> 15, 29, 40, 45, 0, 58, 0, 0, 0, 0, 0, 0, 0, 0, 0, 59, 0, 0, 0, 0,…#> $ time_hour <dttm> 2013-01-01 05:00:00, 2013-01-01 05:00:00, 2013-01-01 05:00:00, 2…View(flights) # 在 RStudio 数据浏览器中打开数据集# tibble::view() 调用 utils::View() 并不可见地返回原数据集,便于 %>% 操作,但速度好像慢很多🤔 想想
05:00
对于如下由行(样本)和列(变量)构成的数据集 / 数据表我们会进行哪些方面的操作呢?
| year | month | day | dep_time | dep_delay | arr_delay | air_time | carrier | origin | dest | |
|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 2013 | 1 | 23 | 1609 | -1 | -18 | 27 | 9E | JFK | PHL |
| 2 | 2013 | 1 | 28 | EV | EWR | STL | ||||
| 3 | 2013 | 2 | 1 | 1747 | -13 | -16 | 43 | US | LGA | BOS |
| 4 | 2013 | 2 | 12 | 839 | -1 | -1 | 45 | 9E | JFK | BOS |
| 5 | 2013 | 3 | 6 | 2006 | 71 | 37 | 185 | UA | LGA | IAH |
| 6 | 2013 | 3 | 14 | 859 | -1 | -7 | 110 | UA | LGA | ORD |
| 7 | 2013 | 3 | 18 | 1323 | -5 | -15 | 327 | UA | EWR | LAX |
| 8 | 2013 | 4 | 9 | 515 | 0 | -24 | 186 | UA | EWR | IAH |
1. 样本处理
(manipulate cases)
>> 样本筛选:filter()
filter(.data, ...):提取数据集 .data 中变量取值满足设定条件的样本
filter(flights, month == 1, day == 1)# 注意:条件表达式中的是 ==,而不是 =#> # A tibble: 842 × 19#> year month day dep_t…¹ sched…² dep_d…³ arr_t…⁴ sched…⁵ arr_d…⁶ carrier flight tailnum#> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr> <int> <chr> #> 1 2013 1 1 517 515 2 830 819 11 UA 1545 N14228 #> 2 2013 1 1 533 529 4 850 830 20 UA 1714 N24211 #> 3 2013 1 1 542 540 2 923 850 33 AA 1141 N619AA #> # … with 839 more rows, 7 more variables: origin <chr>, dest <chr>, air_time <dbl>,#> # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>, and abbreviated variable#> # names ¹dep_time, ²sched_dep_time, ³dep_delay, ⁴arr_time, ⁵sched_arr_time, ⁶arr_delay>> 样本筛选:filter()
filter(.data, ...):提取数据集 .data 中变量取值满足设定条件的样本
filter(flights, month == 1, day == 1)# 注意:条件表达式中的是 ==,而不是 =#> # A tibble: 842 × 19#> year month day dep_t…¹ sched…² dep_d…³ arr_t…⁴ sched…⁵ arr_d…⁶ carrier flight tailnum#> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr> <int> <chr> #> 1 2013 1 1 517 515 2 830 819 11 UA 1545 N14228 #> 2 2013 1 1 533 529 4 850 830 20 UA 1714 N24211 #> 3 2013 1 1 542 540 2 923 850 33 AA 1141 N619AA #> # … with 839 more rows, 7 more variables: origin <chr>, dest <chr>, air_time <dbl>,#> # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>, and abbreviated variable#> # names ¹dep_time, ²sched_dep_time, ³dep_delay, ⁴arr_time, ⁵sched_arr_time, ⁶arr_delay# 在 R 基础包中的实现方法flights[flights$month == 1 & flights$day == 1, ]subset(flights, month == 1 & day == 1)flights[month == 1 & day == 1, ] # 这样写是错滴#> Error in `[.tbl_df`(flights, month == 1 & day == 1, ): object 'month' not found>> 样本筛选:filter()
dplyr 包中的函数(如 filter() )并不会直接修改输入数据集 .data
你必须自行存储修改后的数据集 💾
dec25 <- filter(flights, month == 12, day == 25)dec25#> # A tibble: 719 × 19#> year month day dep_t…¹ sched…² dep_d…³ arr_t…⁴ sched…⁵ arr_d…⁶ carrier flight tailnum#> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr> <int> <chr> #> 1 2013 12 25 456 500 -4 649 651 -2 US 1895 N156UW #> 2 2013 12 25 524 515 9 805 814 -9 UA 1016 N32404 #> 3 2013 12 25 542 540 2 832 850 -18 AA 2243 N5EBAA #> # … with 716 more rows, 7 more variables: origin <chr>, dest <chr>, air_time <dbl>,#> # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>, and abbreviated variable#> # names ¹dep_time, ²sched_dep_time, ³dep_delay, ⁴arr_time, ⁵sched_arr_time, ⁶arr_delayflights#> # A tibble: 336,776 × 19#> year month day dep_t…¹ sched…² dep_d…³ arr_t…⁴ sched…⁵ arr_d…⁶ carrier flight tailnum#> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr> <int> <chr> #> 1 2013 1 1 517 515 2 830 819 11 UA 1545 N14228 #> 2 2013 1 1 533 529 4 850 830 20 UA 1714 N24211 #> 3 2013 1 1 542 540 2 923 850 33 AA 1141 N619AA #> # … with 336,773 more rows, 7 more variables: origin <chr>, dest <chr>, air_time <dbl>,#> # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>, and abbreviated variable#> # names ¹dep_time, ²sched_dep_time, ³dep_delay, ⁴arr_time, ⁵sched_arr_time, ⁶arr_delay>> 样本筛选:filter()
filter() 会用到的比较运算符和逻辑运算符
1. < > <= >= == != # ?Comparison 2. & | ! xor() # ?base::Logic 3. 其它的如:%in%、is.na()、between()、near()等filter() 默认以 & 的方式组合多个条件参数,其它组合方式则要自行设定
filter(flights, month >= 11, day == 25) # 等效于filter(flights, month >= 11 & day == 25)Q:假如我们想挑出11月和12月的航班样本呢?
filter(flights, month == 11 | 12) # 想想,这句会得到什么结果呢?filter(flights, month == (11 | 12)) # 这句呢?>> 样本筛选:filter()
filter() 会用到的比较运算符和逻辑运算符
1. < > <= >= == != # ?Comparison 2. & | ! xor() # ?base::Logic 3. 其它的如:%in%、is.na()、between()、near()等filter() 默认以 & 的方式组合多个条件参数,其它组合方式则要自行设定
filter(flights, month >= 11, day == 25) # 等效于filter(flights, month >= 11 & day == 25)Q:假如我们想挑出11月和12月的航班样本呢?
filter(flights, month == 11 | 12) # 想想,这句会得到什么结果呢?filter(flights, month == (11 | 12)) # 这句呢?filter(flights, month == 11 | month == 12) # 这句才是正确的答案!filter(flights, month %in% c(11, 12)) # 这句也OK!>> 样本筛选:其它函数
slice(.data, ..., .preserve == FALSE):按照整数向量给出的索引位置选择样本,正(负)整数表示保留(移除)的样本,如slice(mtcars, 5:n())slice_head(.data, ..., n, prop)和slice_tail()选择数据集开始 / 结尾的样本 vs.utils::head() / tail()?slice_sample(.data, ..., n, prop, weight_by = NULL, replace = FALSE)随机选择样本slice_min(.data, order_by, ..., n, prop, with_ties = TRUE)和slice_max()选择order_by参数指定的变量或其函数取值最大或最小的样本distinct(.data, ..., .keep_all = FALSE):移除(指定变量或其函数)取值重复的样本 ≈base::unique()
>> 样本筛选:其它函数
slice(.data, ..., .preserve == FALSE):按照整数向量给出的索引位置选择样本,正(负)整数表示保留(移除)的样本,如slice(mtcars, 5:n())slice_head(.data, ..., n, prop)和slice_tail()选择数据集开始 / 结尾的样本 vs.utils::head() / tail()?slice_sample(.data, ..., n, prop, weight_by = NULL, replace = FALSE)随机选择样本slice_min(.data, order_by, ..., n, prop, with_ties = TRUE)和slice_max()选择order_by参数指定的变量或其函数取值最大或最小的样本distinct(.data, ..., .keep_all = FALSE):移除(指定变量或其函数)取值重复的样本 ≈base::unique()
注: 在 dplyrv1.0.0 之后 top_n()、top_frac()、sample_n() 和 sample_frac() 等函数已被相应的 slice_*() 函数所替代
>> 样本排序:arrange()
arrange(.data, ...):根据指定变量的取值对数据集 .data 的样本排序
arrange(flights, year, month, day, dep_time)#> # A tibble: 336,776 × 19#> year month day dep_t…¹ sched…² dep_d…³ arr_t…⁴ sched…⁵ arr_d…⁶ carrier flight tailnum#> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr> <int> <chr> #> 1 2013 1 1 517 515 2 830 819 11 UA 1545 N14228 #> 2 2013 1 1 533 529 4 850 830 20 UA 1714 N24211 #> 3 2013 1 1 542 540 2 923 850 33 AA 1141 N619AA #> # … with 336,773 more rows, 7 more variables: origin <chr>, dest <chr>, air_time <dbl>,#> # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>, and abbreviated variable#> # names ¹dep_time, ²sched_dep_time, ³dep_delay, ⁴arr_time, ⁵sched_arr_time, ⁶arr_delay>> 样本排序:arrange()
arrange(.data, ...):根据指定变量的取值对数据集 .data 的样本排序
arrange(flights, year, month, day, dep_time)#> # A tibble: 336,776 × 19#> year month day dep_t…¹ sched…² dep_d…³ arr_t…⁴ sched…⁵ arr_d…⁶ carrier flight tailnum#> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr> <int> <chr> #> 1 2013 1 1 517 515 2 830 819 11 UA 1545 N14228 #> 2 2013 1 1 533 529 4 850 830 20 UA 1714 N24211 #> 3 2013 1 1 542 540 2 923 850 33 AA 1141 N619AA #> # … with 336,773 more rows, 7 more variables: origin <chr>, dest <chr>, air_time <dbl>,#> # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>, and abbreviated variable#> # names ¹dep_time, ²sched_dep_time, ³dep_delay, ⁴arr_time, ⁵sched_arr_time, ⁶arr_delayarrange(flights, desc(dep_delay)) # 加入 desc() 反向排序:从大到小#> # A tibble: 336,776 × 19#> year month day dep_t…¹ sched…² dep_d…³ arr_t…⁴ sched…⁵ arr_d…⁶ carrier flight tailnum#> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr> <int> <chr> #> 1 2013 1 9 641 900 1301 1242 1530 1272 HA 51 N384HA #> 2 2013 6 15 1432 1935 1137 1607 2120 1127 MQ 3535 N504MQ #> 3 2013 1 10 1121 1635 1126 1239 1810 1109 MQ 3695 N517MQ #> # … with 336,773 more rows, 7 more variables: origin <chr>, dest <chr>, air_time <dbl>,#> # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>, and abbreviated variable#> # names ¹dep_time, ²sched_dep_time, ³dep_delay, ⁴arr_time, ⁵sched_arr_time, ⁶arr_delay>> 样本排序:arrange()
不像 dplyr 包中的其它函数,arrange(.data, ..., .by_group = FALSE) 会忽略数据集的分组信息,除非明确加入分组变量或设定 .by_group = TRUE
缺失值总是排在最后 *
df <- tibble(x = c(5, 2, NA))arrange(df, x)#> # A tibble: 3 × 1#> x#> <dbl>#> 1 2#> 2 5#> 3 NAdf <- tibble(x = c(2, 5, NA))arrange(df, desc(x))#> # A tibble: 3 × 1#> x#> <dbl>#> 1 5#> 2 2#> 3 NA>> 样本排序:arrange()
不像 dplyr 包中的其它函数,arrange(.data, ..., .by_group = FALSE) 会忽略数据集的分组信息,除非明确加入分组变量或设定 .by_group = TRUE
缺失值总是排在最后 *
df <- tibble(x = c(5, 2, NA))arrange(df, x)#> # A tibble: 3 × 1#> x#> <dbl>#> 1 2#> 2 5#> 3 NAdf <- tibble(x = c(2, 5, NA))arrange(df, desc(x))#> # A tibble: 3 × 1#> x#> <dbl>#> 1 5#> 2 2#> 3 NA*:base::sort() 和 base::order() 通过参数 na.last 来控制把缺失值放在哪里或删除,并通过参数 decreasing 来控制排序方向。
2. 变量处理
(manipulate variables)
>> 变量选取:select(.data, ...)
select(flights, month, day, dep_time, sched_dep_time, dep_delay) # 枚举式:变量名,无需""#> # A tibble: 336,776 × 5#> month day dep_time sched_dep_time dep_delay#> <int> <int> <int> <int> <dbl>#> 1 1 1 517 515 2#> 2 1 1 533 529 4#> 3 1 1 542 540 2#> # … with 336,773 more rows>> 变量选取:select(.data, ...)
select(flights, month, day, dep_time, sched_dep_time, dep_delay) # 枚举式:变量名,无需""#> # A tibble: 336,776 × 5#> month day dep_time sched_dep_time dep_delay#> <int> <int> <int> <int> <dbl>#> 1 1 1 517 515 2#> 2 1 1 533 529 4#> 3 1 1 542 540 2#> # … with 336,773 more rowsselect(flights, 2, 3, 4, 5, 6) # 枚举式:表示变量位置的数字,结果同上,但不推荐>> 变量选取:select(.data, ...)
select(flights, month, day, dep_time, sched_dep_time, dep_delay) # 枚举式:变量名,无需""#> # A tibble: 336,776 × 5#> month day dep_time sched_dep_time dep_delay#> <int> <int> <int> <int> <dbl>#> 1 1 1 517 515 2#> 2 1 1 533 529 4#> 3 1 1 542 540 2#> # … with 336,773 more rowsselect(flights, 2, 3, 4, 5, 6) # 枚举式:表示变量位置的数字,结果同上,但不推荐select(flights, month:dep_delay) # 用 : 选择连在一起的变量select(flights, 2:6)>> 变量选取:select(.data, ...)
select(flights, month, day, dep_time, sched_dep_time, dep_delay) # 枚举式:变量名,无需""#> # A tibble: 336,776 × 5#> month day dep_time sched_dep_time dep_delay#> <int> <int> <int> <int> <dbl>#> 1 1 1 517 515 2#> 2 1 1 533 529 4#> 3 1 1 542 540 2#> # … with 336,773 more rowsselect(flights, 2, 3, 4, 5, 6) # 枚举式:表示变量位置的数字,结果同上,但不推荐select(flights, month:dep_delay) # 用 : 选择连在一起的变量select(flights, 2:6)select(flights, !(month:dep_delay)) # 变量前的 ! 或 - 表示剔除#> # A tibble: 336,776 × 14#> year arr_time sched…¹ arr_d…² carrier flight tailnum origin dest air_t…³ dista…⁴ hour#> <int> <int> <int> <dbl> <chr> <int> <chr> <chr> <chr> <dbl> <dbl> <dbl>#> 1 2013 830 819 11 UA 1545 N14228 EWR IAH 227 1400 5#> 2 2013 850 830 20 UA 1714 N24211 LGA IAH 227 1416 5#> 3 2013 923 850 33 AA 1141 N619AA JFK MIA 160 1089 5#> # … with 336,773 more rows, 2 more variables: minute <dbl>, time_hour <dttm>, and#> # abbreviated variable names ¹sched_arr_time, ²arr_delay, ³air_time, ⁴distance>> 变量选取:select(.data, ...)
select() 的帮助函数,已析出到 tidyselect 包中,如:
starts_with("abc"):选取变量名以abc开头的变量ends_with("xyz"):选取变量名以xyz结束的变量contains("ijk"):选取变量名包含ijk的变量matches("(.)\\1"):选取变量名中出现重复字符的变量num_range("x", 1:3):选取变量x1、x2和x3any_of(x) | all_of(x):选择整数向量x指定位置或字符向量x直接指定的变量last_col(offset = 0L):选择从最后算起的第offset+1个的变量everything():全部变量,通常放在最后where(fn):选择满足断言函数fn条件的变量,如select(data, where(is.integer))
>> 变量选取:select(.data, ...)
select() 的帮助函数,已析出到 tidyselect 包中,如:
starts_with("abc"):选取变量名以abc开头的变量ends_with("xyz"):选取变量名以xyz结束的变量contains("ijk"):选取变量名包含ijk的变量matches("(.)\\1"):选取变量名中出现重复字符的变量num_range("x", 1:3):选取变量x1、x2和x3any_of(x) | all_of(x):选择整数向量x指定位置或字符向量x直接指定的变量last_col(offset = 0L):选择从最后算起的第offset+1个的变量everything():全部变量,通常放在最后where(fn):选择满足断言函数fn条件的变量,如select(data, where(is.integer))
select():可混合使用各种方法
select(flights, year:day, ends_with("_delay") | starts_with("dep_"), tailnum)#> # A tibble: 336,776 × 7#> year month day dep_delay arr_delay dep_time tailnum#> <int> <int> <int> <dbl> <dbl> <int> <chr> #> 1 2013 1 1 2 11 517 N14228 #> 2 2013 1 1 4 20 533 N24211 #> 3 2013 1 1 2 33 542 N619AA #> # … with 336,773 more rows>> 变量重命名:select()、rename() 和 rename_with()
select(flights, nian = year, yue = month, ri = day) # 选取变量的同时重命名变量#> # A tibble: 336,776 × 3#> nian yue ri#> <int> <int> <int>#> 1 2013 1 1#> 2 2013 1 1#> 3 2013 1 1#> # … with 336,773 more rows# select() 只保留指定的变量,而 rename(.data, ...) 则会保留全部变量rename(flights, nian = year, yue = month, ri = day) %>% dim()#> [1] 336776 19>> 变量重命名:select()、rename() 和 rename_with()
select(flights, nian = year, yue = month, ri = day) # 选取变量的同时重命名变量#> # A tibble: 336,776 × 3#> nian yue ri#> <int> <int> <int>#> 1 2013 1 1#> 2 2013 1 1#> 3 2013 1 1#> # … with 336,773 more rows# select() 只保留指定的变量,而 rename(.data, ...) 则会保留全部变量rename(flights, nian = year, yue = month, ri = day) %>% dim()#> [1] 336776 19# rename_with(.data, .fn, .cols = everything(), ...)rename_with(flights, toupper, 1:3)#> # A tibble: 336,776 × 19#> YEAR MONTH DAY dep_t…¹ sched…² dep_d…³ arr_t…⁴ sched…⁵ arr_d…⁶ carrier flight tailnum#> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr> <int> <chr> #> 1 2013 1 1 517 515 2 830 819 11 UA 1545 N14228 #> 2 2013 1 1 533 529 4 850 830 20 UA 1714 N24211 #> 3 2013 1 1 542 540 2 923 850 33 AA 1141 N619AA #> # … with 336,773 more rows, 7 more variables: origin <chr>, dest <chr>, air_time <dbl>,#> # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>, and abbreviated variable#> # names ¹dep_time, ²sched_dep_time, ³dep_delay, ⁴arr_time, ⁵sched_arr_time, ⁶arr_delay>> 变量次序调整:select() 和 relocate()
select(flights, dest, year:day, ends_with("_delay"), everything())#> # A tibble: 336,776 × 19#> dest year month day dep_delay arr_d…¹ dep_t…² sched…³ arr_t…⁴ sched…⁵ carrier flight#> <chr> <int> <int> <int> <dbl> <dbl> <int> <int> <int> <int> <chr> <int>#> 1 IAH 2013 1 1 2 11 517 515 830 819 UA 1545#> 2 IAH 2013 1 1 4 20 533 529 850 830 UA 1714#> 3 MIA 2013 1 1 2 33 542 540 923 850 AA 1141#> # … with 336,773 more rows, 7 more variables: tailnum <chr>, origin <chr>,#> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>, and#> # abbreviated variable names ¹arr_delay, ²dep_time, ³sched_dep_time, ⁴arr_time,#> # ⁵sched_arr_time>> 变量次序调整:select() 和 relocate()
select(flights, dest, year:day, ends_with("_delay"), everything())#> # A tibble: 336,776 × 19#> dest year month day dep_delay arr_d…¹ dep_t…² sched…³ arr_t…⁴ sched…⁵ carrier flight#> <chr> <int> <int> <int> <dbl> <dbl> <int> <int> <int> <int> <chr> <int>#> 1 IAH 2013 1 1 2 11 517 515 830 819 UA 1545#> 2 IAH 2013 1 1 4 20 533 529 850 830 UA 1714#> 3 MIA 2013 1 1 2 33 542 540 923 850 AA 1141#> # … with 336,773 more rows, 7 more variables: tailnum <chr>, origin <chr>,#> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>, and#> # abbreviated variable names ¹arr_delay, ²dep_time, ³sched_dep_time, ⁴arr_time,#> # ⁵sched_arr_timerelocate(flights, dest, year:day, ends_with("_delay")) # 结果同上>> 变量次序调整:select() 和 relocate()
select(flights, dest, year:day, ends_with("_delay"), everything())#> # A tibble: 336,776 × 19#> dest year month day dep_delay arr_d…¹ dep_t…² sched…³ arr_t…⁴ sched…⁵ carrier flight#> <chr> <int> <int> <int> <dbl> <dbl> <int> <int> <int> <int> <chr> <int>#> 1 IAH 2013 1 1 2 11 517 515 830 819 UA 1545#> 2 IAH 2013 1 1 4 20 533 529 850 830 UA 1714#> 3 MIA 2013 1 1 2 33 542 540 923 850 AA 1141#> # … with 336,773 more rows, 7 more variables: tailnum <chr>, origin <chr>,#> # air_time <dbl>, distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>, and#> # abbreviated variable names ¹arr_delay, ²dep_time, ³sched_dep_time, ⁴arr_time,#> # ⁵sched_arr_timerelocate(flights, dest, year:day, ends_with("_delay")) # 结果同上# relocate(.data, ..., .before = NULL, .after = NULL)relocate(flights, ends_with("_delay"), .after = day)#> # A tibble: 336,776 × 19#> year month day dep_d…¹ arr_d…² dep_t…³ sched…⁴ arr_t…⁵ sched…⁶ carrier flight tailnum#> <int> <int> <int> <dbl> <dbl> <int> <int> <int> <int> <chr> <int> <chr> #> 1 2013 1 1 2 11 517 515 830 819 UA 1545 N14228 #> 2 2013 1 1 4 20 533 529 850 830 UA 1714 N24211 #> 3 2013 1 1 2 33 542 540 923 850 AA 1141 N619AA #> # … with 336,773 more rows, 7 more variables: origin <chr>, dest <chr>, air_time <dbl>,#> # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>, and abbreviated variable#> # names ¹dep_delay, ²arr_delay, ³dep_time, ⁴sched_dep_time, ⁵arr_time, ⁶sched_arr_time>> 生成新变量:mutate()
mutate(.data, ...):生成新变量 *
flights_sml <- select(flights, year:day, ends_with("_delay"), air_time)mutate(flights_sml, gain = arr_delay - dep_delay, hours = air_time / 60, gain_per_hour = gain / hours # 可直接引用新生成的变量)#> # A tibble: 336,776 × 9#> year month day dep_delay arr_delay air_time gain hours gain_per_hour#> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>#> 1 2013 1 1 2 11 227 9 3.78 2.38#> 2 2013 1 1 4 20 227 16 3.78 4.23#> 3 2013 1 1 2 33 160 31 2.67 11.6 #> # … with 336,773 more rows>> 生成新变量:mutate()
mutate(.data, ...):生成新变量 *
flights_sml <- select(flights, year:day, ends_with("_delay"), air_time)mutate(flights_sml, gain = arr_delay - dep_delay, hours = air_time / 60, gain_per_hour = gain / hours # 可直接引用新生成的变量)#> # A tibble: 336,776 × 9#> year month day dep_delay arr_delay air_time gain hours gain_per_hour#> <int> <int> <int> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>#> 1 2013 1 1 2 11 227 9 3.78 2.38#> 2 2013 1 1 4 20 227 16 3.78 4.23#> 3 2013 1 1 2 33 160 31 2.67 11.6 #> # … with 336,773 more rows*:1. dplyrv1.0.0 给 mutate() 新增了三个实验性参数 .keep = c("all", "used", "unused", "none")、.before = NULL 和 .after = NULL;
2. 假如你只想保留新生成的变量,那就使用 设定 transmute() 或mutate() 参数 .keep = "none"
>> 生成新变量:mutate()
mutate():支持向量化函数 *
MATH +, - , *, /, ^, %/%, %% # arithmetic ops log(), log2(), log10() # logs <, <=, >, >=, !=, == # logical comparisonsCUMULATIVE AGGREGATES # vignette("window-functions") dplyr::cumall()|cumany() # cumulative all() | any() cummax()|cummin() # cumulative max() | min() dplyr::cummean() # cumulative mean() cumprod()|cumsum() # cumulative prod() | sum()OFFSETS dplyr::lag()|lead() # offset elements by 1 | -1RANKINGS # ?ranking dplyr::min_rank() # rank with ties = min dplyr::ntile() # bins into n bins dplyr::row_number() # rank with ties = "first"MISC pmax()|pmin() # element-wise max() | min() dplyr::recode() # vectorized switch() dplyr::if_else() # vectorized if() + else() dplyr::case_when() # multi-case if_else()>> 生成新变量:mutate()
mutate():支持向量化函数 *
MATH +, - , *, /, ^, %/%, %% # arithmetic ops log(), log2(), log10() # logs <, <=, >, >=, !=, == # logical comparisonsCUMULATIVE AGGREGATES # vignette("window-functions") dplyr::cumall()|cumany() # cumulative all() | any() cummax()|cummin() # cumulative max() | min() dplyr::cummean() # cumulative mean() cumprod()|cumsum() # cumulative prod() | sum()OFFSETS dplyr::lag()|lead() # offset elements by 1 | -1RANKINGS # ?ranking dplyr::min_rank() # rank with ties = min dplyr::ntile() # bins into n bins dplyr::row_number() # rank with ties = "first"MISC pmax()|pmin() # element-wise max() | min() dplyr::recode() # vectorized switch() dplyr::if_else() # vectorized if() + else() dplyr::case_when() # multi-case if_else()*:当然也支持返回“标量”的汇总函数,如 mean(),会将标量直接扩展至需要的长度。
>> 生成新变量:mutate()
多列操作 👉 vignette("colwise")
# ?scoped# *_all() 作用于每个变量# *_at() 作用于用 vars() 函数、字符向量或位置向量指定的变量# *_if() 作用于 .predicate 函数取值为 TRUE 的变量mutate_all(.tbl, .funs, ...)mutate_at(.tbl, .vars, .funs, ...)mutate_if(.tbl, .predicate, .funs, ...)# transmute()、summarise()、group_by()、arrange()、filter()、rename()等函数也有类似的变体函数但上述变体函数在 dplyrv1.0.0 中已被更具优势的 across(.cols = everything(), .fns = NULL, ..., .names = NULL) 所替代
>> 生成新变量:mutate()
多列操作 👉 vignette("colwise")
# ?scoped# *_all() 作用于每个变量# *_at() 作用于用 vars() 函数、字符向量或位置向量指定的变量# *_if() 作用于 .predicate 函数取值为 TRUE 的变量mutate_all(.tbl, .funs, ...)mutate_at(.tbl, .vars, .funs, ...)mutate_if(.tbl, .predicate, .funs, ...)# transmute()、summarise()、group_by()、arrange()、filter()、rename()等函数也有类似的变体函数但上述变体函数在 dplyrv1.0.0 中已被更具优势的 across(.cols = everything(), .fns = NULL, ..., .names = NULL) 所替代
mutate(flights_sml, across(dep_delay:air_time, ~ .x / 60)) # 这是什么鬼?!:(# mutate_at(flights_sml, vars(dep_delay:air_time), ~ .x / 60)#> # A tibble: 336,776 × 6#> year month day dep_delay arr_delay air_time#> <int> <int> <int> <dbl> <dbl> <dbl>#> 1 2013 1 1 0.0333 0.183 3.78#> 2 2013 1 1 0.0667 0.333 3.78#> 3 2013 1 1 0.0333 0.55 2.67#> # … with 336,773 more rows3. 汇总
(summarise)
>> 汇总:summarise()
summarise(.data, ..., .groups = NULL)函数生成新的数据框,每个汇总函数占一列(假如汇总函数返回多列数据框,则占多列),每个分组占用一行(假如汇总函数返回多个值或多行数据框,则占用多行);此外,假如.data是分组数据框 👇,则每个分组变量还会占一列。- 可用实验性参数
.groups = c("drop_last", "drop", "keep", "rowwise")来控制新生成结果数据框的分组结构。
summarise( flights, mean_delay = mean(dep_delay, na.rm = TRUE), sd_delay = sd(dep_delay, na.rm = TRUE), qt_delay = quantile(dep_delay, probs = seq(0, 1, 0.25), na.rm = TRUE), probs = seq(0, 1, 0.25))#> # A tibble: 5 × 4#> mean_delay sd_delay qt_delay probs#> <dbl> <dbl> <dbl> <dbl>#> 1 12.6 40.2 -43 0 #> 2 12.6 40.2 -5 0.25#> 3 12.6 40.2 -2 0.5 #> 4 12.6 40.2 11 0.75#> 5 12.6 40.2 1301 1>> 汇总:summarise()
dplyrv1.0.0 极大扩展了 summarise() 的灵活性,允许其返回包含多个元素的向量甚至是多列的数据框(之前版本只支持返回“标量”的汇总函数,部分函数如下表所示)
COUNTS dplyr::n() # number of values/rows dplyr::n_distinct() # number of uniques sum(!is.na()) # number of non-NA’sLOCATION mean() | median() # mean | medianPOSITION/ORDER dplyr::first() # first value dplyr::last() # last value dplyr::nth() # value in n-th location of vectorRANK quantile() # nth quantile min() | max() # minimum value | maximum valueSPREAD IQR() # Inter-Quartile Range mad() # median absolute deviation sd() # standard deviation var() # variance4. 分组和行式处理
(grouping and rowwise)
>> 分组处理:group_by() 👉 vignette("grouping")
group_by(.data, ..., .add = FALSE, .drop = group_by_drop_default(.data))将数据框及其扩展转变为分组数据框(grouped_df)
by_day <- group_by(flights, year, month, day)class(by_day)#> [1] "grouped_df" "tbl_df" "tbl" #> [4] "data.frame"by_day#> # A tibble: 336,776 × 19#> # Groups: year, month, day [365]#> year month day dep_time sched_…¹ dep_d…²#> <int> <int> <int> <int> <int> <dbl>#> 1 2013 1 1 517 515 2#> 2 2013 1 1 533 529 4#> 3 2013 1 1 542 540 2#> # … with 336,773 more rows, 13 more#> # variables: arr_time <int>,#> # sched_arr_time <int>, arr_delay <dbl>,#> # carrier <chr>, flight <int>,#> # tailnum <chr>, origin <chr>, dest <chr>,#> # air_time <dbl>, distance <dbl>,#> # hour <dbl>, minute <dbl>, …>> 分组处理:group_by() 👉 vignette("grouping")
group_by(.data, ..., .add = FALSE, .drop = group_by_drop_default(.data))将数据框及其扩展转变为分组数据框(grouped_df)
by_day <- group_by(flights, year, month, day)class(by_day)#> [1] "grouped_df" "tbl_df" "tbl" #> [4] "data.frame"by_day#> # A tibble: 336,776 × 19#> # Groups: year, month, day [365]#> year month day dep_time sched_…¹ dep_d…²#> <int> <int> <int> <int> <int> <dbl>#> 1 2013 1 1 517 515 2#> 2 2013 1 1 533 529 4#> 3 2013 1 1 542 540 2#> # … with 336,773 more rows, 13 more#> # variables: arr_time <int>,#> # sched_arr_time <int>, arr_delay <dbl>,#> # carrier <chr>, flight <int>,#> # tailnum <chr>, origin <chr>, dest <chr>,#> # air_time <dbl>, distance <dbl>,#> # hour <dbl>, minute <dbl>, …获取分组元数据的相关函数
by_day %>% group_vars()#> [1] "year" "month" "day"by_day %>% group_data()#> # A tibble: 365 × 4#> year month day .rows#> <int> <int> <int> <list<int>>#> 1 2013 1 1 [842]#> 2 2013 1 2 [943]#> 3 2013 1 3 [914]#> # … with 362 more rows# group_keys() / # group_rows() / group_indices()# group_size() / n_groups()>> 分组处理:group_by() 👉 vignette("grouping")
group_by()对数据框的分组设定会影响后续 dplyr 包的函数操作,如mutate()、summarise()、filter()、slice()等;如果你不需要基于分组进行后续操作,可先用ungroup(x, ...)函数来取消对数据集x(基于指定变量...)的分组设定
# 分组汇总# 返回结果默认情况下会去除最低一级分组,# 除非设定参数 .groups = 'keep'summarise( by_day, mean_delay = mean( dep_delay, na.rm = TRUE ))#> # A tibble: 365 × 4#> # Groups: year, month [12]#> year month day mean_delay#> <int> <int> <int> <dbl>#> 1 2013 1 1 11.5#> 2 2013 1 2 13.9#> 3 2013 1 3 11.0#> # … with 362 more rows>> 分组处理:group_by() 👉 vignette("grouping")
group_by()对数据框的分组设定会影响后续 dplyr 包的函数操作,如mutate()、summarise()、filter()、slice()等;如果你不需要基于分组进行后续操作,可先用ungroup(x, ...)函数来取消对数据集x(基于指定变量...)的分组设定
# 分组汇总# 返回结果默认情况下会去除最低一级分组,# 除非设定参数 .groups = 'keep'summarise( by_day, mean_delay = mean( dep_delay, na.rm = TRUE ))#> # A tibble: 365 × 4#> # Groups: year, month [12]#> year month day mean_delay#> <int> <int> <int> <dbl>#> 1 2013 1 1 11.5#> 2 2013 1 2 13.9#> 3 2013 1 3 11.0#> # … with 362 more rows# 假如你觉得 group_by() + summarise()不够强# 大,你还可以使用实验性的 purrr-style 函数,# 如 group_map()/*_modify()/*_walk() 等group_modify( by_day, ~ broom::tidy( # what's this?! lm(arr_delay ~ dep_delay, data=.x) ))#> # A tibble: 730 × 8#> # Groups: year, month, day [365]#> year month day term estim…¹ std.e…²#> <int> <int> <int> <chr> <dbl> <dbl>#> 1 2013 1 1 (Interce… 0.910 0.579 #> 2 2013 1 1 dep_delay 1.03 0.0124#> 3 2013 1 2 (Interce… -1.32 0.581 #> # … with 727 more rows, 2 more variables:#> # statistic <dbl>, p.value <dbl>, and#> # abbreviated variable names ¹estimate,#> # ²std.error>> 行式处理:rowwise()
rowwise(data, ...)允许你对数据框的每一行进行运算,当不存在相应的向量化函数时,进行逐行式运算可以让你避免编写显性循环的代码- 和
group_by()类似,rowwise()并不更改数据框的结构,而是让后续的 dplyr 函数操作按逐行式进行 rowwise()返回的是一种特殊的行分组数据框(rowwise_df,每行一组),绝大多数的 dplyr 函数会保留数据框的行分组信息(返回grouped_df的summarise()函数是个例外);你可以通过ungroup()或as_tibble()函数来取消行分组,或通过group_by()函数转变为grouped_df
>> 行式处理:rowwise()
rowwise(data, ...)允许你对数据框的每一行进行运算,当不存在相应的向量化函数时,进行逐行式运算可以让你避免编写显性循环的代码- 和
group_by()类似,rowwise()并不更改数据框的结构,而是让后续的 dplyr 函数操作按逐行式进行 rowwise()返回的是一种特殊的行分组数据框(rowwise_df,每行一组),绝大多数的 dplyr 函数会保留数据框的行分组信息(返回grouped_df的summarise()函数是个例外);你可以通过ungroup()或as_tibble()函数来取消行分组,或通过group_by()函数转变为grouped_df
flights_rw <- rowwise(flights_sml)class(flights_rw)#> [1] "rowwise_df" "tbl_df" "tbl" #> [4] "data.frame"flights_rw#> # A tibble: 336,776 × 6#> # Rowwise: #> year month day dep_delay arr_delay air_time#> <int> <int> <int> <dbl> <dbl> <dbl>#> 1 2013 1 1 2 11 227#> 2 2013 1 1 4 20 227#> 3 2013 1 1 2 33 160#> # … with 336,773 more rows>> 行式处理:rowwise()
rowwise(data, ...)允许你对数据框的每一行进行运算,当不存在相应的向量化函数时,进行逐行式运算可以让你避免编写显性循环的代码- 和
group_by()类似,rowwise()并不更改数据框的结构,而是让后续的 dplyr 函数操作按逐行式进行 rowwise()返回的是一种特殊的行分组数据框(rowwise_df,每行一组),绝大多数的 dplyr 函数会保留数据框的行分组信息(返回grouped_df的summarise()函数是个例外);你可以通过ungroup()或as_tibble()函数来取消行分组,或通过group_by()函数转变为grouped_df
flights_rw <- rowwise(flights_sml)class(flights_rw)#> [1] "rowwise_df" "tbl_df" "tbl" #> [4] "data.frame"flights_rw#> # A tibble: 336,776 × 6#> # Rowwise: #> year month day dep_delay arr_delay air_time#> <int> <int> <int> <dbl> <dbl> <dbl>#> 1 2013 1 1 2 11 227#> 2 2013 1 1 4 20 227#> 3 2013 1 1 2 33 160#> # … with 336,773 more rows# long time to runmutate( flights_rw, max_delay = max(c_across(ends_with("_delay"))))#> # A tibble: 336,776 × 7#> # Rowwise: #> year month day dep_delay arr_d…¹ air_t…²#> <int> <int> <int> <dbl> <dbl> <dbl>#> 1 2013 1 1 2 11 227#> 2 2013 1 1 4 20 227#> 3 2013 1 1 2 33 160#> # … with 336,773 more rows, 1 more variable:#> # max_delay <dbl>, and abbreviated#> # variable names ¹arr_delay, ²air_time>> 行式处理:rowwise()
一个稍微复杂(但思路类似的)例子
nest_flights <- nest_by( flights_sml, year, month, day)nest_flights#> # A tibble: 365 × 4#> # Rowwise: year, month, day#> year month day data#> <int> <int> <int> <list<tibble[,3]>>#> 1 2013 1 1 [842 × 3]#> 2 2013 1 2 [943 × 3]#> 3 2013 1 3 [914 × 3]#> 4 2013 1 4 [915 × 3]#> 5 2013 1 5 [720 × 3]#> # … with 360 more rows>> 行式处理:rowwise()
一个稍微复杂(但思路类似的)例子
nest_flights <- nest_by( flights_sml, year, month, day)nest_flights#> # A tibble: 365 × 4#> # Rowwise: year, month, day#> year month day data#> <int> <int> <int> <list<tibble[,3]>>#> 1 2013 1 1 [842 × 3]#> 2 2013 1 2 [943 × 3]#> 3 2013 1 3 [914 × 3]#> 4 2013 1 4 [915 × 3]#> 5 2013 1 5 [720 × 3]#> # … with 360 more rowstransmute( nest_flights, mean_delay = mean( data$dep_delay, na.rm = TRUE ))#> # A tibble: 365 × 4#> # Rowwise: year, month, day#> year month day mean_delay#> <int> <int> <int> <dbl>#> 1 2013 1 1 11.5 #> 2 2013 1 2 13.9 #> 3 2013 1 3 11.0 #> 4 2013 1 4 8.95#> 5 2013 1 5 5.73#> # … with 360 more rows>> 行式处理:rowwise()
一个稍微复杂(但思路类似的)例子
nest_flights <- nest_by( flights_sml, year, month, day)nest_flights#> # A tibble: 365 × 4#> # Rowwise: year, month, day#> year month day data#> <int> <int> <int> <list<tibble[,3]>>#> 1 2013 1 1 [842 × 3]#> 2 2013 1 2 [943 × 3]#> 3 2013 1 3 [914 × 3]#> 4 2013 1 4 [915 × 3]#> 5 2013 1 5 [720 × 3]#> # … with 360 more rowstransmute( nest_flights, mean_delay = mean( data$dep_delay, na.rm = TRUE ))#> # A tibble: 365 × 4#> # Rowwise: year, month, day#> year month day mean_delay#> <int> <int> <int> <dbl>#> 1 2013 1 1 11.5 #> 2 2013 1 2 13.9 #> 3 2013 1 3 11.0 #> 4 2013 1 4 8.95#> 5 2013 1 5 5.73#> # … with 360 more rows👉 vignette("rowwise")
5. 用 %>% 连接多个操作
(chaining multiple operations with the pipe %>%)
>> 管道运算符:%>%
不用 %>% 的代码
by_dest <- group_by(flights, dest)delay <- summarise( by_dest, count = n(), dist = mean(distance, na.rm = TRUE), delay = mean(arr_delay, na.rm = TRUE))delay <- filter(delay, count > 20, dest != "HNL")ggplot(delay, aes(x = dist, y = delay)) + geom_point(aes(size = count), alpha = 1/3) + geom_smooth(se = FALSE)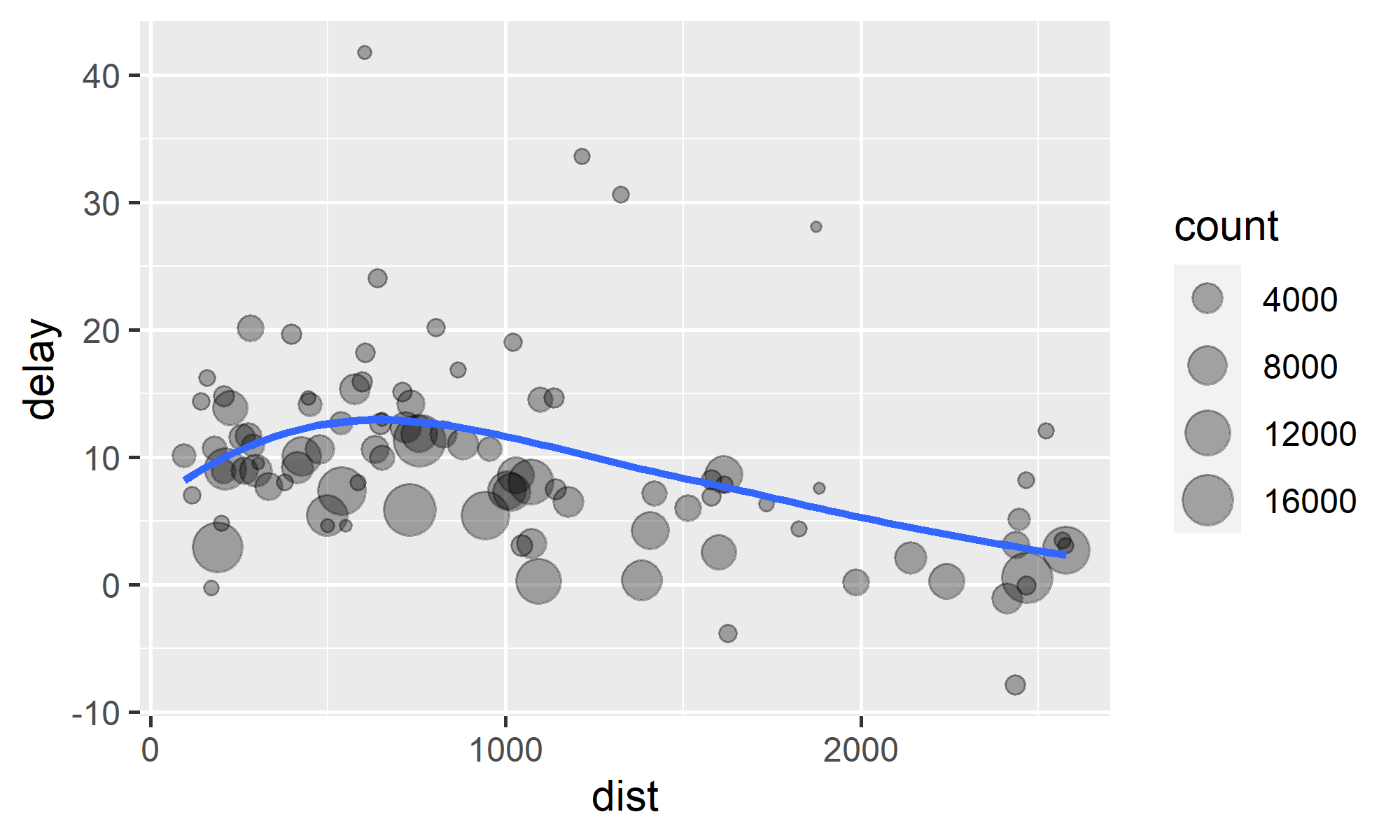
>> 管道运算符:%>%
使用 %>% 的代码( %>% 来自 magrittr 包,快捷键为 Ctrl+Shift+M )
# 用 %>% 改写前一页的代码flights %>% group_by(dest) %>% summarise( count = n(), dist = mean(distance, na.rm = TRUE), delay = mean(arr_delay, na.rm = TRUE) ) %>% filter(count > 20, dest != "HNL") %>% ggplot(aes(x = dist, y = delay)) + geom_point(aes(size = count), alpha = 1/3) + geom_smooth(se = FALSE)>> 管道运算符:%>%
使用 %>% 的代码( %>% 来自 magrittr 包,快捷键为 Ctrl+Shift+M )
# 用 %>% 改写前一页的代码flights %>% group_by(dest) %>% summarise( count = n(), dist = mean(distance, na.rm = TRUE), delay = mean(arr_delay, na.rm = TRUE) ) %>% filter(count > 20, dest != "HNL") %>% ggplot(aes(x = dist, y = delay)) + geom_point(aes(size = count), alpha = 1/3) + geom_smooth(se = FALSE)dplyr包会在后台自动将x %>% f(y)转变为f(x, y),将x %>% f(y, .)转变为f(y, x),将x %>% f(y, z = .)转变为f(y, z = x)……使用
%>%编写的代码关注动词(如数据变换操作)而非名词(操作对象),这使得代码更容易写,更容易读,也更容易修改让函数兼容管道操作符是
tidyverse的{{核心原则}}之一,dplyr包的函数就具备这样的特性:f(.data01, ...) -> .data02,“数据进,数据出”,更适用于管道操作
>> 管道运算符:%>%
yet again but with R's native forward pipe operator |>
not_cancelled <- flights |> filter(!is.na(dep_delay), !is.na(arr_delay))not_cancelled |> group_by(year, month, day) |> summarise( first = dep_time |> min(), last = dep_time %>% max, avg_delay1 = mean(arr_delay), avg_delay2 = mean(arr_delay[arr_delay > 0]) # average pos delay )#> # A tibble: 365 × 7#> # Groups: year, month [12]#> year month day first last avg_delay1 avg_delay2#> <int> <int> <int> <int> <int> <dbl> <dbl>#> 1 2013 1 1 517 2356 12.7 32.5#> 2 2013 1 2 42 2354 12.7 32.0#> 3 2013 1 3 32 2349 5.73 27.7#> # … with 362 more rows🙋♂️ Your Turn!
05:00
利用管道操作符 %>% 改写以下 # 重嵌套的代码:
summarise( select( group_by(starwars, species, sex), height, mass ), height = mean(height, na.rm = TRUE), mass = mean(mass, na.rm = TRUE))#> # A tibble: 41 × 4#> # Groups: species [38]#> species sex height mass#> <chr> <chr> <dbl> <dbl>#> 1 Aleena male 79 15#> 2 Besalisk male 198 102#> 3 Cerean male 198 82#> # … with 38 more rowsstarwars %>% group_by(species, sex) %>% select(height, mass) %>% summarise( height = mean(height, na.rm = TRUE), mass = mean(mass, na.rm = TRUE) )#> # A tibble: 41 × 4#> # Groups: species [38]#> species sex height mass#> <chr> <chr> <dbl> <dbl>#> 1 Aleena male 79 15#> 2 Besalisk male 198 102#> 3 Cerean male 198 82#> # … with 38 more rows6. 合并数据集
(combine tables)
airlines#> # A tibble: 16 × 2#> carrier name #> <chr> <chr> #> 1 9E Endeavor Air Inc. #> 2 AA American Airlines Inc.#> 3 AS Alaska Airlines Inc. #> # … with 13 more rowsplanes#> # A tibble: 3,322 × 9#> tailnum year type manuf…¹ model engines#> <chr> <int> <chr> <chr> <chr> <int>#> 1 N10156 2004 Fixed … EMBRAER EMB-… 2#> 2 N102UW 1998 Fixed … AIRBUS… A320… 2#> 3 N103US 1999 Fixed … AIRBUS… A320… 2#> # … with 3,319 more rows, 3 more variables:#> # seats <int>, speed <int>, engine <chr>,#> # and abbreviated variable name#> # ¹manufacturerairlines#> # A tibble: 16 × 2#> carrier name #> <chr> <chr> #> 1 9E Endeavor Air Inc. #> 2 AA American Airlines Inc.#> 3 AS Alaska Airlines Inc. #> # … with 13 more rowsplanes#> # A tibble: 3,322 × 9#> tailnum year type manuf…¹ model engines#> <chr> <int> <chr> <chr> <chr> <int>#> 1 N10156 2004 Fixed … EMBRAER EMB-… 2#> 2 N102UW 1998 Fixed … AIRBUS… A320… 2#> 3 N103US 1999 Fixed … AIRBUS… A320… 2#> # … with 3,319 more rows, 3 more variables:#> # seats <int>, speed <int>, engine <chr>,#> # and abbreviated variable name#> # ¹manufacturerairports#> # A tibble: 1,458 × 8#> faa name lat lon alt tz dst #> <chr> <chr> <dbl> <dbl> <dbl> <dbl> <chr>#> 1 04G Lansdo… 41.1 -80.6 1044 -5 A #> 2 06A Moton … 32.5 -85.7 264 -6 A #> 3 06C Schaum… 42.0 -88.1 801 -6 A #> # … with 1,455 more rows, and 1 more#> # variable: tzone <chr>weather#> # A tibble: 26,115 × 15#> origin year month day hour temp dewp#> <chr> <int> <int> <int> <int> <dbl> <dbl>#> 1 EWR 2013 1 1 1 39.0 26.1#> 2 EWR 2013 1 1 2 39.0 27.0#> 3 EWR 2013 1 1 3 39.0 28.0#> # … with 26,112 more rows, and 8 more#> # variables: humid <dbl>, wind_dir <dbl>,#> # wind_speed <dbl>, wind_gust <dbl>,#> # precip <dbl>, pressure <dbl>,#> # visib <dbl>, time_hour <dttm>>> 键(keys)
主键(primary key):指的是数据表中一列或多列的组合,其值能唯一地标识表中的每一行。主键主要用来与其他表的外键关联,以及本表的修改与删除。
planes %>% count(tailnum) %>% filter(n > 1)#> # A tibble: 0 × 2#> # … with 2 variables: tailnum <chr>, n <int>weather %>% count(year, month, day, hour, origin) %>% filter(n > 1)#> # A tibble: 3 × 6#> year month day hour origin n#> <int> <int> <int> <int> <chr> <int>#> 1 2013 11 3 1 EWR 2#> 2 2013 11 3 1 JFK 2#> 3 2013 11 3 1 LGA 2weather <- weather %>% distinct(year, month, day, hour, origin) # 修正之>> 键(keys)
主键(primary key):指的是数据表中一列或多列的组合,其值能唯一地标识表中的每一行。主键主要用来与其他表的外键关联,以及本表的修改与删除。
planes %>% count(tailnum) %>% filter(n > 1)#> # A tibble: 0 × 2#> # … with 2 variables: tailnum <chr>, n <int>weather %>% count(year, month, day, hour, origin) %>% filter(n > 1)#> # A tibble: 3 × 6#> year month day hour origin n#> <int> <int> <int> <int> <chr> <int>#> 1 2013 11 3 1 EWR 2#> 2 2013 11 3 1 JFK 2#> 3 2013 11 3 1 LGA 2weather <- weather %>% distinct(year, month, day, hour, origin) # 修正之外键(foreign key):可用来唯一标识另一数据表中的每一行。
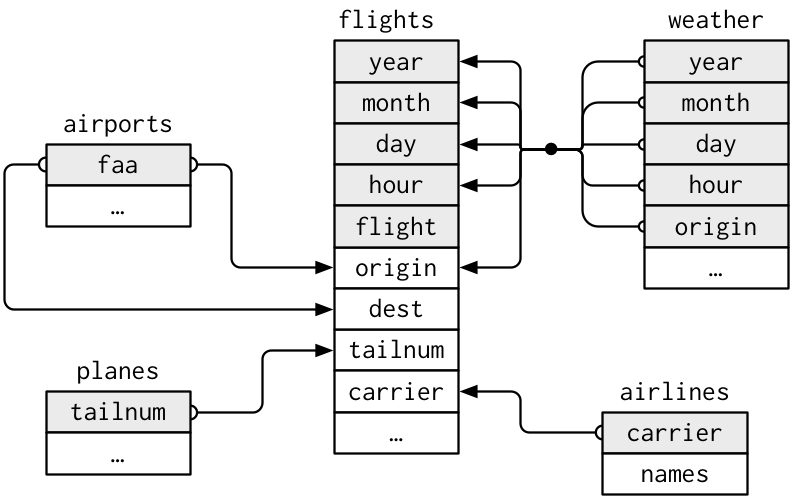
>> 合并式连接(mutating joins)
*_join(x, y, by = NULL, copy = FALSE, suffix = c(".x", ".y"), ...)
flights %>% select(year:day, hour, tailnum, carrier) %>% left_join(airlines, by = "carrier")#> # A tibble: 336,776 × 7#> year month day hour tailnum carrier name #> <int> <int> <int> <dbl> <chr> <chr> <chr> #> 1 2013 1 1 5 N14228 UA United Air Lines Inc. #> 2 2013 1 1 5 N24211 UA United Air Lines Inc. #> 3 2013 1 1 5 N619AA AA American Airlines Inc.#> # … with 336,773 more rows>> 合并式连接(mutating joins)
*_join(x, y, by = NULL, copy = FALSE, suffix = c(".x", ".y"), ...)
flights %>% select(year:day, hour, tailnum, carrier) %>% left_join(airlines, by = "carrier")#> # A tibble: 336,776 × 7#> year month day hour tailnum carrier name #> <int> <int> <int> <dbl> <chr> <chr> <chr> #> 1 2013 1 1 5 N14228 UA United Air Lines Inc. #> 2 2013 1 1 5 N24211 UA United Air Lines Inc. #> 3 2013 1 1 5 N619AA AA American Airlines Inc.#> # … with 336,773 more rowsflights %>% select(year:day, hour, tailnum, carrier) %>% mutate(name = airlines$name[match(carrier, airlines$carrier)]) # 殊途同归,但容易理解吗?#> # A tibble: 336,776 × 7#> year month day hour tailnum carrier name #> <int> <int> <int> <dbl> <chr> <chr> <chr> #> 1 2013 1 1 5 N14228 UA United Air Lines Inc. #> 2 2013 1 1 5 N24211 UA United Air Lines Inc. #> 3 2013 1 1 5 N619AA AA American Airlines Inc.#> # … with 336,773 more rows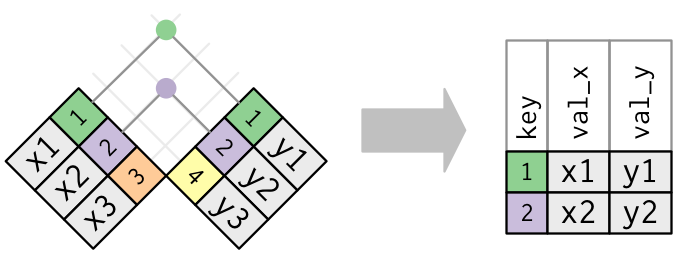
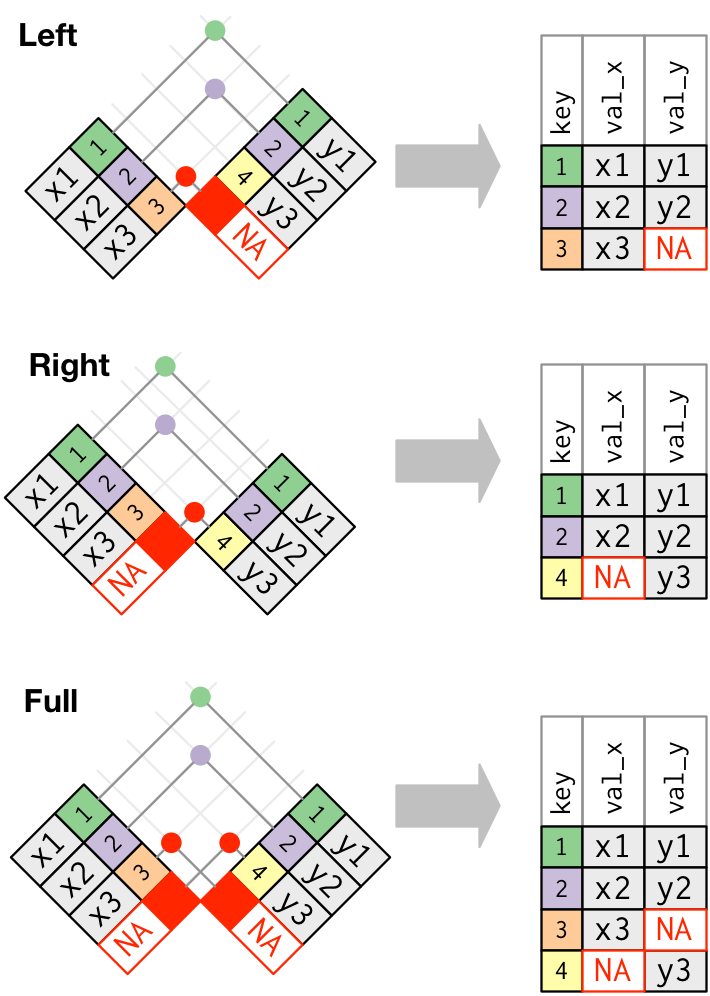
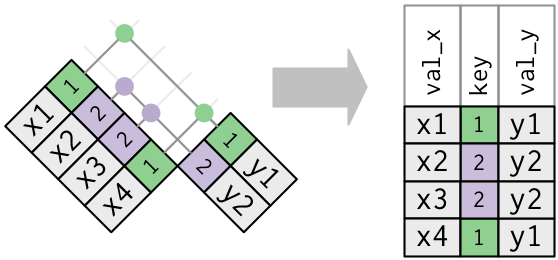
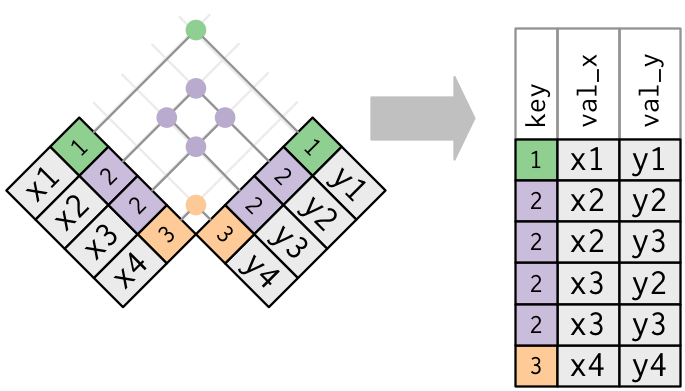
>> 合并式连接(mutating joins)
用 by 参数设定连接所用的键变量
# 设定`by = 字符向量`flights %>% left_join(weather, by = c("year", "month", "day", "origin", "hour"))# 设定`by = 命名字符向量`flights %>% left_join(airports, by = c("dest" = "faa"))# *natural join*# 未设定by参数(即`by = NULL`),默认使用两个数据集中同名的全部变量,# 此时会显示提示信息“Joining, by = c(同名变量列表)”flights %>% left_join(weather)>> 筛选式连接(filtering joins)
semi_join(x, y, by = NULL, copy = FALSE, ...) | anti_join()
保留 | 丢弃 x 数据集中在 y 数据集中找得到匹配的样本
top_dest <- flights %>% count(dest, sort = TRUE) %>% head(10)flights %>% filter(dest %in% top_dest$dest)#> # A tibble: 141,145 × 19#> year month day dep_t…¹ sched…² dep_d…³ arr_t…⁴ sched…⁵ arr_d…⁶ carrier flight tailnum#> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr> <int> <chr> #> 1 2013 1 1 542 540 2 923 850 33 AA 1141 N619AA #> 2 2013 1 1 554 600 -6 812 837 -25 DL 461 N668DN #> 3 2013 1 1 554 558 -4 740 728 12 UA 1696 N39463 #> # … with 141,142 more rows, 7 more variables: origin <chr>, dest <chr>, air_time <dbl>,#> # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>, and abbreviated variable#> # names ¹dep_time, ²sched_dep_time, ³dep_delay, ⁴arr_time, ⁵sched_arr_time, ⁶arr_delay>> 筛选式连接(filtering joins)
semi_join(x, y, by = NULL, copy = FALSE, ...) | anti_join()
保留 | 丢弃 x 数据集中在 y 数据集中找得到匹配的样本
top_dest <- flights %>% count(dest, sort = TRUE) %>% head(10)flights %>% filter(dest %in% top_dest$dest)#> # A tibble: 141,145 × 19#> year month day dep_t…¹ sched…² dep_d…³ arr_t…⁴ sched…⁵ arr_d…⁶ carrier flight tailnum#> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr> <int> <chr> #> 1 2013 1 1 542 540 2 923 850 33 AA 1141 N619AA #> 2 2013 1 1 554 600 -6 812 837 -25 DL 461 N668DN #> 3 2013 1 1 554 558 -4 740 728 12 UA 1696 N39463 #> # … with 141,142 more rows, 7 more variables: origin <chr>, dest <chr>, air_time <dbl>,#> # distance <dbl>, hour <dbl>, minute <dbl>, time_hour <dttm>, and abbreviated variable#> # names ¹dep_time, ²sched_dep_time, ³dep_delay, ⁴arr_time, ⁵sched_arr_time, ⁶arr_delayflights %>% semi_join(top_dest)# 相同的结果,但更容易处理 filter() + %in% 难以处理的存在多个 key 变量的情况>> 其它类型的合并
嵌套式连接
nest_join(x, y, by = NULL, copy = FALSE, keep = FALSE, name = NULL, ...)保留x,并将匹配的y数据作为新增的列表列(元素为tibble),当y数据集中找不到匹配数据时,列表列相应位置则填充一个0行的tibble从某种意义上说,
nest_join()是最基础的数据集连接操作函数:inner_join()等于nest_join() + tidyr::unnest(),left_join()等于nest_join() + unnest(.keep_empty = TRUE),而semi_join()和anti_join()则等于nest_join() + filter()(filter()用来检查列表列中元素是否为0行的tibble)
>> 其它类型的合并
嵌套式连接
nest_join(x, y, by = NULL, copy = FALSE, keep = FALSE, name = NULL, ...)保留x,并将匹配的y数据作为新增的列表列(元素为tibble),当y数据集中找不到匹配数据时,列表列相应位置则填充一个0行的tibble从某种意义上说,
nest_join()是最基础的数据集连接操作函数:inner_join()等于nest_join() + tidyr::unnest(),left_join()等于nest_join() + unnest(.keep_empty = TRUE),而semi_join()和anti_join()则等于nest_join() + filter()(filter()用来检查列表列中元素是否为0行的tibble)
用 y 表中的数据来修订 x 表中的行
rows_insert(x, y, by = NULL, ...)|rows_update()|rows_upsert()rows_delete()rows_append()|rows_patch()
合并多个数据集的行或列
bind_rows(..., .id = NULL)
# do.call(rbind, dfs_list)bind_cols(..., .name_repair)
# do.call(cbind, dfs_list)
集合式合并
intersect(x, y, ...)setdiff(x, y, ...)union(x, y, ...)|union_all()
7. 操作数据库和 data.table
>> 连接并查询数据库
除了处理内存中以 tibble 或 data.frame 格式存在的数据集之外,dplyr 包还可用于处理存储在主流数据库中的数据,这主要适用于两种情形:
- 数据已经存储在数据库中
- 数据太大无法直接存入内存中,必须使用外部存储
这需要你额外安装 dbplyr 包2.2.1(会自动安装其需要载入的 DBI 包)以及你打算连接的不同数据库的接口 R 包(如 RPostgres、RMariaDB、odbc 等)。
以下我们以SQLite数据库为例说明。
准备工作
# install.packages("dbplyr")# install.packages("RSQLite")# library(dplyr)con <- DBI::dbConnect( RSQLite::SQLite(), dbname = ":memory:" )copy_to( con, nycflights13::flights, "flights", overwrite = TRUE, indexes = list( c("year", "month", "day"), "carrier", "tailnum", "dest"))>> 连接并查询数据库
# 创建对数据表的引用并列印结果(flights_db <- tbl(con, "flights"))#> # Source: table<flights> [?? x 19]#> # Database: sqlite 3.39.4 [:memory:]#> year month day dep_time sched_dep…¹ dep_d…² arr_t…³ sched…⁴ arr_d…⁵ carrier#> <int> <int> <int> <int> <int> <dbl> <int> <int> <dbl> <chr> #> 1 2013 1 1 517 515 2 830 819 11 UA #> 2 2013 1 1 533 529 4 850 830 20 UA #> 3 2013 1 1 542 540 2 923 850 33 AA #> # … with more rows, 9 more variables: flight <int>, tailnum <chr>,#> # origin <chr>, dest <chr>, air_time <dbl>, distance <dbl>, hour <dbl>,#> # minute <dbl>, time_hour <dbl>, and abbreviated variable names#> # ¹sched_dep_time, ²dep_delay, ³arr_time, ⁴sched_arr_time, ⁵arr_delay# 生成查询tailnum_delay_db <- flights_db %>% group_by(tailnum) %>% summarise( delay = mean(arr_delay), n = n() ) %>% arrange(desc(delay)) %>% filter(n > 100)>> 连接并查询数据库
tailnum_delay_db %>% show_query()#> <SQL>#> SELECT *#> FROM (#> SELECT `tailnum`, AVG(`arr_delay`) AS `delay`, COUNT(*) AS `n`#> FROM `flights`#> GROUP BY `tailnum`#> )#> WHERE (`n` > 100.0)tailnum_delay <- tailnum_delay_db %>% collect()tailnum_delay#> # A tibble: 1,201 × 3#> tailnum delay n#> <chr> <dbl> <int>#> 1 <NA> NA 2512#> 2 N0EGMQ 9.98 371#> 3 N10156 12.7 153#> # … with 1,198 more rows>> 操作 data.table
data.table 是 data.table 包提供的一种数据结构,是升级版的 data.frame:
- 简洁的语法,
x[i, j, by] - 时间/内存高效的数据操作,如文件读取/输出、数据提取、汇总、更新、合并等
- 兼容只接受
data.frame数据格式的其它 R 包
dplyr 包允许你以 dplyr 的方式操作 data.table,后台的 dtplyr 包1.2.2会自动将其转译为等价的 data.table 语法。
# install.packages("dtplyr")library(dtplyr)# library(data.table)library(dplyr, warn.conflicts = FALSE)# 创建一个lazy data.table,追踪对其的操作flights_dt <- lazy_dt(nycflights13::flights)# 操作data.tableflights_dt %>% mutate(arr_delay = arr_delay/60) %>% group_by(tailnum) %>% summarise( across(ends_with("_delay"), mean), n = n() ) %>% arrange(desc(arr_delay)) %>% filter(n > 100)# Use as.data.table()/as.data.frame()/# as_tibble() to access results#> Source: local data table [1,201 x 4]#> Call: copy(`_DT1`)[, `:=`(arr_delay = arr_delay/60)][, .(dep_delay = mean(dep_delay), #> arr_delay = mean(arr_delay), n = .N), keyby = .(tailnum)][order(-arr_delay)][n > #> 100]#> #> tailnum dep_delay arr_delay n#> <chr> <dbl> <dbl> <int>#> 1 N826UA 26.7 0.326 120#> 2 N929DL 25.3 0.293 108#> 3 N431UA 23.9 0.272 104#> 4 N342NW 21.1 0.267 111#> 5 N567UA 18.7 0.250 105#> 6 N850UA 23.9 0.248 130#> # … with 1,195 more rows#> #> # Use as.data.table()/as.data.frame()/as_tibble() to access results课后练习
🕐 复习 📖 R for Data Science 一书的第5章、第13章和第18章的内容并(结队)完成(自选)课后练习
🕑 下载(打印) 📰 {{dplyr的cheatsheet}} 并阅读之
🕒 browseVignettes(package = "dplyr") 📝
🕓 安装 qfwr 包并完成练习 L05 👩💻